

Η Google φέρνει νέα μοντέλα παραγωγής στο Vertex AI, συμπεριλαμβανομένου του Imagen
Related Posts
Προς την
παράφραση
Ο Andreessen Horowitz, η γενετική τεχνητή νοημοσύνη, ιδιαίτερα από την πλευρά του text-to-art, τρώει τον κόσμο. Τουλάχιστον, οι επενδυτές το πιστεύουν – αν κρίνουμε από τα δισεκατομμύρια δολάρια που έχουν διαθέσει σε νεοφυείς επιχειρήσεις που αναπτύσσουν τεχνητή νοημοσύνη που δημιουργεί κείμενο και εικόνες από προτροπές.
Για να μην μείνει πίσω, η Big Tech επενδύει στις δικές της παραγωγικές λύσεις τέχνης τεχνητής νοημοσύνης, είτε μέσω συνεργασιών με τις προαναφερθείσες νεοφυείς επιχειρήσεις είτε μέσω εσωτερικής έρευνας και ανάπτυξης. (Βλέπε: Η Microsoft συνεργάζεται με το OpenAI for Image Creator.) Η Google, αξιοποιώντας την ισχυρή της πτέρυγα Ε&Α, αποφάσισε να ακολουθήσει την τελευταία οδό, εμπορευματοποιώντας τη δουλειά της στη γενετική τεχνητή νοημοσύνη για να ανταγωνιστεί τις πλατφόρμες που υπάρχουν ήδη.
Σήμερα στο ετήσιο συνέδριο προγραμματιστών I/O, η Google ανακοίνωσε νέα μοντέλα τεχνητής νοημοσύνης που κατευθύνονται στην Vertex AI, την πλήρως διαχειριζόμενη υπηρεσία AI της, συμπεριλαμβανομένου ενός μοντέλου κειμένου σε εικόνα που ονομάζεται Imagen. Το Imagen, το οποίο η Google έκανε προεπισκόπηση μέσω της εφαρμογής AI Test Kitchen τον περασμένο Νοέμβριο, μπορεί να δημιουργήσει και να επεξεργαστεί εικόνες καθώς και να γράψει λεζάντες για υπάρχουσες εικόνες.
“Οποιοσδήποτε προγραμματιστής μπορεί να χρησιμοποιήσει αυτήν την τεχνολογία χρησιμοποιώντας το Google Cloud”, δήλωσε στο TechCrunch σε τηλεφωνική συνέντευξη ο Nenshad Bardoliwalla, διευθυντής της Vertex AI στο Google Cloud. “Δεν χρειάζεται να είστε επιστήμονας δεδομένων ή προγραμματιστής.”
Εικόνα σε Vertex
Το να ξεκινήσετε με το Imagen στο Vertex είναι πράγματι μια σχετικά απλή διαδικασία. Μια διεπαφή χρήστη για το μοντέλο είναι προσβάσιμη από αυτό που η Google αποκαλεί Model Garden, μια επιλογή μοντέλων που έχει αναπτύξει η Google μαζί με επιμελημένα μοντέλα ανοιχτού κώδικα. Εντός της διεπαφής χρήστη, παρόμοια με τις πλατφόρμες δημιουργικής τέχνης, όπως το MidJourney και το Nightcafe, οι πελάτες μπορούν να εισάγουν μηνύματα (π.χ. “μια μωβ τσάντα”) για να δημιουργήσουν το Imagen μια χούφτα υποψήφιων εικόνων.
Τα εργαλεία επεξεργασίας και οι επακόλουθες προτροπές βελτιώνουν τις εικόνες που δημιουργούνται από το Imagen, για παράδειγμα προσαρμόζοντας το χρώμα των αντικειμένων που απεικονίζονται σε αυτές. Το Vertex προσφέρει επίσης αναβάθμιση για την ευκρίνεια των εικόνων, εκτός από τη λεπτομέρεια που επιτρέπει στους πελάτες να κατευθύνουν το Imagen προς ορισμένα στυλ και προτιμήσεις.
Όπως αναφέρθηκε προηγουμένως, το Imagen μπορεί επίσης να δημιουργήσει υπότιτλους για εικόνες, μεταφράζοντας προαιρετικά αυτούς τους υπότιτλους αξιοποιώντας τη Μετάφραση Google. Για συμμόρφωση με τους κανονισμούς απορρήτου όπως ο GDPR, οι εικόνες που δημιουργούνται που δεν αποθηκεύονται διαγράφονται εντός 24 ωρών,
λέει ο Bardoliwalla.
«Καθιστούμε πολύ εύκολο για τους ανθρώπους να αρχίσουν να εργάζονται με τη γενετική τεχνητή νοημοσύνη και τις εικόνες τους».
αυτός πρόσθεσε.
Φυσικά, υπάρχει μια σειρά από ηθικές και νομικές προκλήσεις που σχετίζονται με όλες τις μορφές παραγωγικής τεχνητής νοημοσύνης — ανεξάρτητα από το πόσο εκλεπτυσμένη είναι η διεπαφή χρήστη. Μοντέλα τεχνητής νοημοσύνης όπως το Imagen «μαθαίνουν» να δημιουργούν εικόνες από μηνύματα κειμένου «εκπαιδεύοντας» σε υπάρχουσες εικόνες, οι οποίες συχνά προέρχονται από σύνολα δεδομένων που αποκόπηκαν μεταξύ τους με τράτα ιστοτόπων φιλοξενίας δημόσιων εικόνων. Ορισμένοι ειδικοί προτείνουν ότι τα μοντέλα εκπαίδευσης που χρησιμοποιούν δημόσιες εικόνες, ακόμη και εκείνες που προστατεύονται από πνευματικά δικαιώματα, θα καλύπτονται από το
δόγμα ορθής χρήσης
στις ΗΠΑ Αλλά είναι ένα θέμα που είναι
απίθανος
να διευθετηθεί σύντομα.
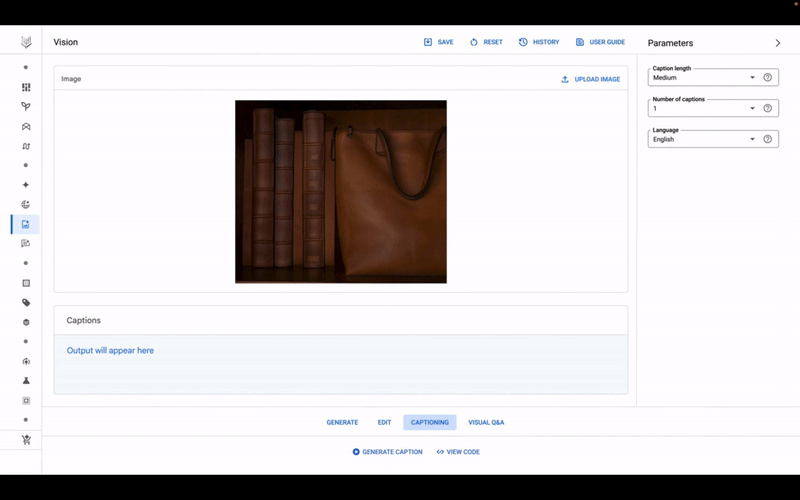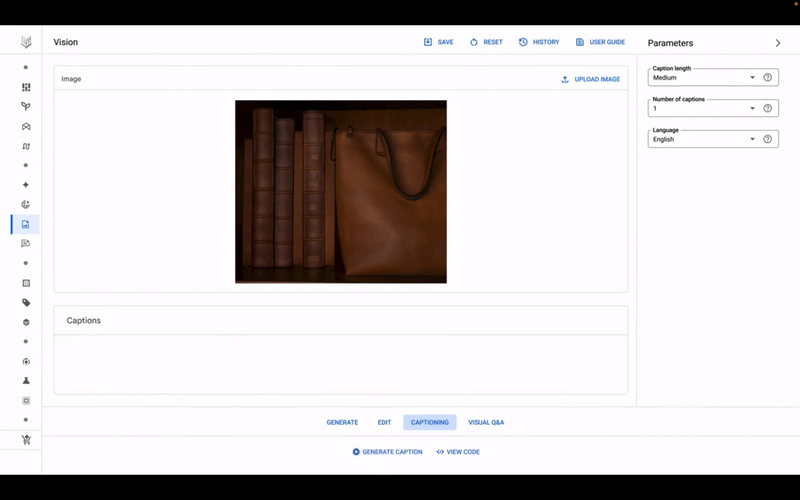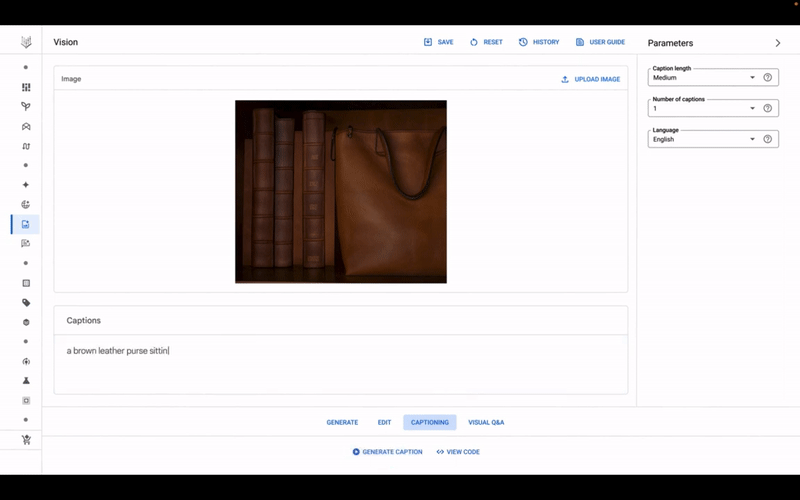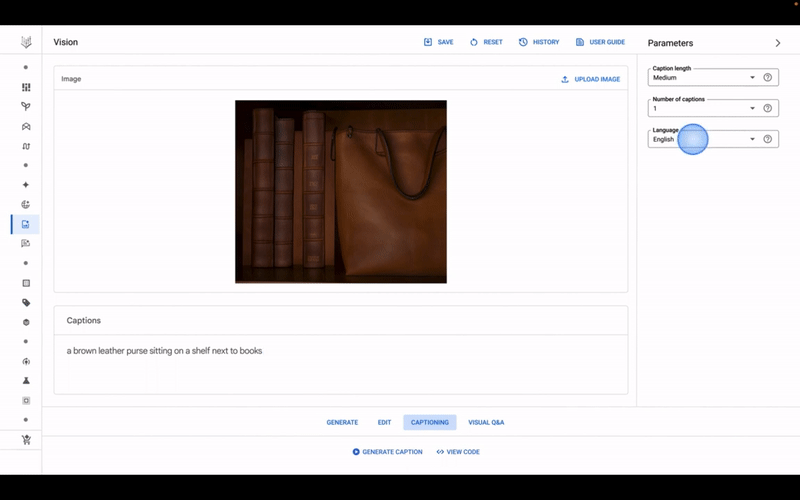
Το μοντέλο Imagen της Google σε δράση, στο Vertex AI.
Στην πραγματικότητα, δύο εταιρείες πίσω από δημοφιλή εργαλεία τέχνης AI, η Midjourney και η Stability AI, βρίσκονται στο στόχαστρο μιας
νομική υπόθεση
που ισχυρίζεται ότι παραβίασαν τα δικαιώματα εκατομμυρίων καλλιτεχνών εκπαιδεύοντας τα εργαλεία τους σε εικόνες γραμμένες στον ιστό. Ο προμηθευτής φωτογραφιών Getty Images οδήγησε το Stability AI στο δικαστήριο, ξεχωριστά
σύμφωνα με πληροφορίες
χρησιμοποιώντας εκατομμύρια εικόνες από τον ιστότοπό του χωρίς άδεια για να εκπαιδεύσει το μοντέλο παραγωγής τέχνης Stable Diffusion.
ρώτησα
Bardoliwalla αν οι πελάτες της Vertex θα πρέπει να ανησυχούν ότι η Imagen μπορεί να έχει εκπαιδευτεί σε υλικό που προστατεύεται από πνευματικά δικαιώματα. Όπως είναι λογικό, θα μπορούσαν να αποθαρρυνθούν από το να το χρησιμοποιήσουν αν συνέβαινε αυτό.
Ο Bardoliwalla δεν είπε ξεκάθαρα ότι το Imagen δεν είχε εκπαιδευτεί σε εικόνες με εμπορικά σήματα — μόνο ότι η Google διενεργεί εκτενείς “ελέγχους διακυβέρνησης δεδομένων” για να “εξετάσει τα δεδομένα πηγής” μέσα στα μοντέλα της για να διασφαλίσει ότι δεν έχουν αξιώσεις πνευματικών δικαιωμάτων. (Η αντισταθμισμένη γλώσσα δεν αποτελεί τεράστια έκπληξη λαμβάνοντας υπόψη ότι η
πρωτότυπο Imagen
εκπαιδεύτηκε σε ένα δημόσιο σύνολο δεδομένων,
ΛΑΙΟΝ
γνωστό ότι περιέχει έργα που προστατεύονται από πνευματικά δικαιώματα.)
“Πρέπει να βεβαιωθούμε ότι είμαστε απόλυτα εντός της ισορροπίας του σεβασμού όλων των νόμων που αφορούν τις πληροφορίες πνευματικών δικαιωμάτων.”
ο Μπαρδολιβάλα συνέχισε. “Είμαστε πολύ σαφείς με τους πελάτες ότι τους παρέχουμε μοντέλα που μπορούν να αισθάνονται σίγουροι ότι μπορούν να χρησιμοποιήσουν στην εργασία τους και ότι κατέχουν την IP που δημιουργείται από τα εκπαιδευμένα μοντέλα τους με απόλυτα ασφαλή τρόπο.”
Η κατοχή της IP είναι άλλο θέμα. Τουλάχιστον στις ΗΠΑ
δεν είναι ξεκάθαρο
εάν η τέχνη που δημιουργείται από την τεχνητή νοημοσύνη προστατεύεται από πνευματικά δικαιώματα.
Μια λύση —όχι στο πρόβλημα της ιδιοκτησίας, καθεαυτό, αλλά σε ερωτήσεις σχετικά με τα δεδομένα εκπαίδευσης που προστατεύονται από πνευματικά δικαιώματα— είναι να επιτραπεί στους καλλιτέχνες να «εξαιρούνται» από την εκπαίδευση τεχνητής νοημοσύνης συνολικά. Η startup τεχνητής νοημοσύνης Spawning επιχειρεί να καθιερώσει πρότυπα και εργαλεία σε ολόκληρη τη βιομηχανία για την εξαίρεση από τη γενετική τεχνολογία AI. Η Adobe επιδιώκει τους δικούς της μηχανισμούς και εργαλεία εξαίρεσης. Το ίδιο και η DeviantArt, η οποία τον Νοέμβριο ξεκίνησε μια προστασία βασισμένη σε ετικέτες HTML για να απαγορεύσει στα ρομπότ λογισμικού να ανιχνεύουν σελίδες για εικόνες.

Συντελεστές εικόνας:
Google
Η Google δεν προσφέρει επιλογή εξαίρεσης. (Για να είμαστε δίκαιοι, ούτε ένας από τους κύριους αντιπάλους του, το OpenAI.)
Ο Bardoliwalla δεν είπε αν αυτό μπορεί να αλλάξει στο μέλλον, μόνο ότι η Google είναι “
ανησυχεί υπερβολικά» για να διασφαλίσει ότι εκπαιδεύει τα μοντέλα με τρόπο «ηθικό και υπεύθυνο».
Αυτό είναι λίγο πλούσιο, νομίζω, προερχόμενο από μια εταιρεία που
ακυρώθηκε
ένα εξωτερικό συμβούλιο ηθικής τεχνητής νοημοσύνης, εξανάγκασε εξέχοντες ερευνητές ηθικής τεχνητής νοημοσύνης και είναι
περιορισμός
δημοσίευση έρευνας AI για «ανταγωνισμό και διατήρηση της γνώσης στο σπίτι». Αλλά ερμηνεύστε
Τα λόγια του Bardoliwalla όπως θέλετε.
ρώτησα κι εγώ
Μπαρδολιβάλα
σχετικά με τα βήματα που λαμβάνει η Google, εάν υπάρχουν, για να περιορίσει την ποσότητα του τοξικού ή μεροληπτικού περιεχομένου που δημιουργεί το Imagen — ένα άλλο πρόβλημα με τα συστήματα παραγωγής τεχνητής νοημοσύνης. Μόλις πρόσφατα, ερευνητές της startup τεχνητής νοημοσύνης Hugging Face και του Πανεπιστημίου της Λειψίας δημοσίευσαν ένα
εργαλείο
αποδεικνύοντας ότι μοντέλα όπως το Stable Diffusion και το DALL-E 2 του OpenAI τείνουν να παράγουν εικόνες ανθρώπων που φαίνονται λευκοί και αρσενικοί, ειδικά όταν τους ζητείται να απεικονίσουν άτομα σε θέσεις εξουσίας.
Ο Bardoliwalla είχε προετοιμάσει μια πιο λεπτομερή απάντηση για αυτήν την ερώτηση, υποστηρίζοντας ότι κάθε κλήση API σε γενετικά μοντέλα που φιλοξενούνται από το Vertex αξιολογείται για «χαρακτηριστικά ασφαλείας», συμπεριλαμβανομένης της τοξικότητας, της βίας και της άσεμνης συμπεριφοράς. Η Vertex βαθμολογεί μοντέλα σε αυτά τα χαρακτηριστικά και, για ορισμένες κατηγορίες, μπλοκάρει την απόκριση ή δίνει στους πελάτες τη δυνατότητα να επιλέξουν πώς να προχωρήσουν, είπε ο Bardoliwalla.
«Έχουμε μια πολύ καλή αντίληψη από τις καταναλωτικές μας ιδιότητες για τον τύπο περιεχομένου που μπορεί να μην είναι το είδος περιεχομένου που οι πελάτες μας αναζητούν αυτά τα παραγωγικά μοντέλα τεχνητής νοημοσύνης για να παράγουν».
συνέχισε. “Αυτό
είναι ένας τομέας σημαντικών επενδύσεων καθώς και ηγετικής θέσης στην αγορά για την Google — για να διασφαλίσουμε ότι οι πελάτες μας είναι σε θέση να παράγουν τα αποτελέσματα που αναζητούν, τα οποία δεν βλάπτουν ή βλάπτουν την αξία της επωνυμίας τους.”
Για το σκοπό αυτό, η Google λανσάρει την ενισχυτική μάθηση από την ανθρώπινη ανατροφοδότηση (RLHF) ως προσφορά διαχειριζόμενης υπηρεσίας στο Vertex, η οποία, όπως υποστηρίζει, θα βοηθήσει τους οργανισμούς να διατηρήσουν την απόδοση του μοντέλου με την πάροδο του χρόνου και να αναπτύξουν ασφαλέστερα — και μετρήσιμα πιο ακριβή — μοντέλα στην παραγωγή. Το RLHF, μια δημοφιλής τεχνική στη μηχανική μάθηση, εκπαιδεύει ένα «μοντέλο ανταμοιβής» απευθείας από την ανθρώπινη ανατροφοδότηση, όπως ζητώντας από συμβασιούχους εργαζόμενους να βαθμολογήσουν τις απαντήσεις από ένα chatbot AI. Στη συνέχεια, χρησιμοποιεί αυτό το μοντέλο ανταμοιβής για να βελτιστοποιήσει ένα παραγωγικό μοντέλο AI σύμφωνα με τις γραμμές του Imagen.
Συντελεστές εικόνας:
Google
Ο Bardoliwalla λέει ότι το ποσό της τελειοποίησης που απαιτείται
Το RLHF θα εξαρτηθεί από το εύρος του προβλήματος που προσπαθεί να λύσει ένας πελάτης. Υπάρχει συζήτηση εντός του ακαδημαϊκού κόσμου για το αν η RLHF είναι πάντα η σωστή προσέγγιση — η εκκίνηση τεχνητής νοημοσύνης, Anthropic, για ένα, υποστηρίζει ότι δεν είναι, εν μέρει επειδή η RLHF μπορεί να συνεπάγεται την πρόσληψη πολλών χαμηλόμισθων εργολάβων που είναι
αναγκαστικά
για να βαθμολογήσετε εξαιρετικά τοξικό περιεχόμενο. Αλλά η Google αισθάνεται διαφορετικά.
“Με την υπηρεσία RLHF, ένας πελάτης μπορεί να επιλέξει μια μέθοδο και το μοντέλο και στη συνέχεια να βαθμολογήσει τις απαντήσεις που προέρχονται από το μοντέλο.”
είπε ο Μπαρδολιβάλα. «Μια φορά αυτοί
υποβάλετε αυτές τις απαντήσεις στην υπηρεσία ενισχυτικής μάθησης, συντονίζει το μοντέλο για να δημιουργήσει καλύτερες απαντήσεις που ευθυγραμμίζονται με … αυτό που αναζητά ένας οργανισμός.
Νέα μοντέλα και εργαλεία
Πέρα από το Imagen, αρκετά άλλα μοντέλα παραγωγής τεχνητής νοημοσύνης είναι πλέον διαθέσιμα σε επιλεγμένους πελάτες της Vertex, ανακοίνωσε σήμερα η Google: Codey και Chirp.
Το Codey, η απάντηση της Google στο Copilot του GitHub, μπορεί να δημιουργήσει κώδικα σε περισσότερες από 20 γλώσσες, συμπεριλαμβανομένων των Go, Java, Javascript, Python και Typescript. Το Codey μπορεί να προτείνει τις επόμενες γραμμές με βάση το πλαίσιο του κώδικα που εισάγεται σε μια προτροπή ή, όπως το ChatGPT του OpenAI, το μοντέλο μπορεί να απαντήσει σε ερωτήσεις σχετικά με τον εντοπισμό σφαλμάτων, την τεκμηρίωση και τις έννοιες κωδικοποίησης υψηλού επιπέδου.

Συντελεστές εικόνας:
Google
Όσο για το Chirp, είναι ένα μοντέλο ομιλίας που εκπαιδεύεται “εκατομμύρια” ώρες ήχου που υποστηρίζει περισσότερες από 100 γλώσσες και μπορεί να χρησιμοποιηθεί για τη δημιουργία υπότιτλων βίντεο, την παροχή φωνητικής βοήθειας και γενικά την τροφοδοσία μιας σειράς εργασιών ομιλίας και εφαρμογών.
Σε μια σχετική ανακοίνωση στο I/O, η Google κυκλοφόρησε το Embeddings API for Vertex σε προεπισκόπηση, το οποίο μπορεί να μετατρέψει δεδομένα κειμένου και εικόνας σε αναπαραστάσεις που ονομάζονται διανύσματα που χαρτογραφούν συγκεκριμένες σημασιολογικές σχέσεις. Η Google λέει ότι θα χρησιμοποιηθεί για τη δημιουργία λειτουργιών σημασιολογικής αναζήτησης και ταξινόμησης κειμένου, όπως chatbot Q&A με βάση τα δεδομένα ενός οργανισμού, την ανάλυση συναισθημάτων και τον εντοπισμό ανωμαλιών.
Το Codey, το Imagen, το Embeddings API για εικόνες και το RLHF είναι διαθέσιμα στο Vertex AI σε «έμπιστους δοκιμαστές», λέει η Google. Στο μεταξύ, το Chirp, το Embeddings API και το Generative AI Studio, μια σουίτα για αλληλεπίδραση και ανάπτυξη μοντέλων τεχνητής νοημοσύνης, είναι προσβάσιμα σε προεπισκόπηση στο Vertex σε οποιονδήποτε έχει λογαριασμό Google Cloud.

