
V-JEPA: Η απάντηση του Meta στην σύνθετη κατανόηση βίντεο
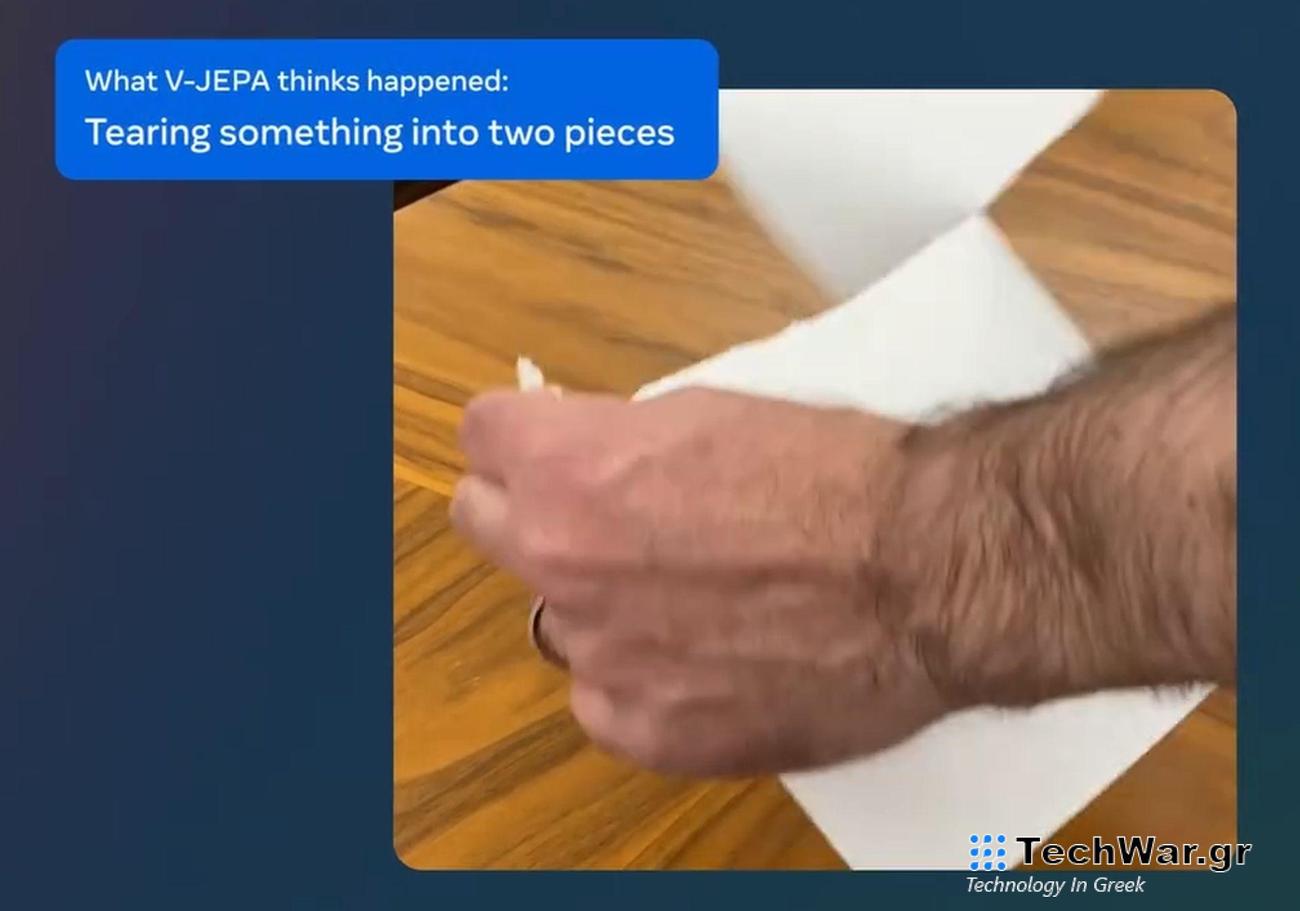
Η τελευταία καινοτομία της Meta, το μοντέλο V-JEPA, είναι εδώ για να αλλάξει τον τρόπο με τον οποίο οι υπολογιστές κατανοούν τα βίντεο. Σε αντίθεση με τις παραδοσιακές μεθόδους, το V-JEPA εστιάζει στην κατανόηση της ευρύτερης εικόνας, διευκολύνοντας τις μηχανές να ερμηνεύουν τις αλληλεπιδράσεις μεταξύ αντικειμένων και σκηνών.
Ποιο είναι το νέο μοντέλο V-JEPA της Meta;
Το νέο μοντέλο V-JEPA της Meta, ή το Video Joint Embedding Predictive Architecture, είναι μια τεχνολογία αιχμής που αναπτύχθηκε για την κατανόηση των βίντεο με τρόπο παρόμοιο με τον τρόπο που κάνουν οι άνθρωποι. Σε αντίθεση με τις παραδοσιακές μεθόδους που εστιάζουν σε μικροσκοπικές λεπτομέρειες, το V-JEPA εξετάζει τη μεγαλύτερη εικόνα, όπως η κατανόηση των αλληλεπιδράσεων μεταξύ αντικειμένων και σκηνών.
Είναι το V-JEPA γενετικό;
Σε αντίθεση με το νέο εργαλείο τεχνητής νοημοσύνης κειμένου σε βίντεο του OpenAI, το Sora AI, το μοντέλο V-JEPA της Meta δεν είναι παραγωγικό. Σε αντίθεση με τα μοντέλα παραγωγής που προσπαθούν να ανακατασκευάσουν τμήματα ενός βίντεο που λείπουν σε επίπεδο pixel, το μοντέλο εστιάζει στην πρόβλεψη περιοχών που λείπουν ή καλύπτονται σε έναν χώρο αφηρημένης αναπαράστασης. Αυτό σημαίνει ότι το μοντέλο δεν δημιουργεί νέο περιεχόμενο ούτε συμπληρώνει απευθείας τα εικονοστοιχεία που λείπουν. Αντίθετα, μαθαίνει να κατανοεί το περιεχόμενο και τις αλληλεπιδράσεις στα βίντεο σε υψηλότερο επίπεδο αφαίρεσης, επιτρέποντας πιο αποτελεσματική μάθηση και προσαρμογή σε όλες τις εργασίες.
Πίστωση εικόνας
)
Αυτό που κάνει το V-JEPA ξεχωριστό είναι το πώς μαθαίνει. Αντί να χρειάζεται πολλά παραδείγματα με ετικέτες, μαθαίνει από βίντεο χωρίς να χρειάζεται ετικέτες. Είναι σαν το πώς τα μωρά μαθαίνουν απλά βλέποντας και δεν χρειάζονται κάποιον να τους πει τι συμβαίνει. Αυτό κάνει τη μάθηση πιο γρήγορη και πιο αποτελεσματική. Εστιάζει στον εντοπισμό τμημάτων ενός βίντεο που λείπουν με έξυπνο τρόπο, αντί να προσπαθεί να συμπληρώσει κάθε λεπτομέρεια. Αυτό το βοηθά να μαθαίνει πιο γρήγορα και να κατανοεί τι είναι σημαντικό σε μια σκηνή.
Ένα άλλο ωραίο πράγμα για το V-JEPA είναι ότι μπορεί να προσαρμοστεί σε νέες εργασίες χωρίς να χρειάζεται να ξαναμάθετε τα πάντα από την αρχή. Αυτό εξοικονομεί πολύ χρόνο και προσπάθεια σε σύγκριση με παλαιότερες μεθόδους που έπρεπε να ξεκινήσουν από την αρχή για κάθε νέα εργασία.
Για να λάβετε τον κωδικό, κάντε κλικ
εδώ
και επισκεφθείτε τη σελίδα του στο GitHub.
Βλέποντας τη μεγαλύτερη εικόνα: Γιατί είναι σημαντικό το V-JEPA;
Το V-JEPA της Meta είναι ένα μεγάλο βήμα προς τα εμπρός στην τεχνητή νοημοσύνη, καθιστώντας ευκολότερο για τους υπολογιστές να κατανοούν τα βίντεο όπως οι άνθρωποι. Είναι μια συναρπαστική εξέλιξη που ανοίγει νέες δυνατότητες, όπως:
-
Κατανοώντας τα βίντεο σαν άνθρωποι
: Το V-JEPA αντιπροσωπεύει μια αξιοσημείωτη πρόοδο στον τομέα της τεχνητής νοημοσύνης, ιδιαίτερα στον τομέα της κατανόησης βίντεο. Η ικανότητά του να κατανοεί τα βίντεο σε βαθύτερο επίπεδο, παρόμοιο με την ανθρώπινη γνώση, σηματοδοτεί ένα σημαντικό βήμα προόδου στην έρευνα της τεχνητής νοημοσύνης.

Πίστωση εικόνας
)
-
Αποτελεσματική μάθηση και προσαρμογή
: Μία από τις βασικές πτυχές του μοντέλου είναι το αυτοεποπτευόμενο παράδειγμα μάθησης. Μαθαίνοντας από δεδομένα χωρίς ετικέτα και απαιτώντας ελάχιστα παραδείγματα με ετικέτα για προσαρμογή σε συγκεκριμένες εργασίες, το V-JEPA προσφέρει μια πιο αποτελεσματική προσέγγιση μάθησης σε σύγκριση με τις παραδοσιακές μεθόδους. Αυτή η αποτελεσματικότητα είναι ζωτικής σημασίας για την κλιμάκωση των συστημάτων τεχνητής νοημοσύνης και τη μείωση της εξάρτησης από τον εκτεταμένο ανθρώπινο σχολιασμό. -
Γενίκευση και πολυχρηστικότητα
: Η ικανότητα του V-JEPA να γενικεύει τη μάθησή του σε διάφορες εργασίες είναι αξιοσημείωτη. Η προσέγγιση «παγωμένης αξιολόγησης» του επιτρέπει την επαναχρησιμοποίηση προεκπαιδευμένων εξαρτημάτων, καθιστώντας το προσαρμόσιμο σε διάφορες εφαρμογές χωρίς την ανάγκη εκτεταμένης επανεκπαίδευσης. Αυτή η ευελιξία είναι απαραίτητη για την αντιμετώπιση διαφορετικών προκλήσεων στην έρευνα τεχνητής νοημοσύνης και σε εφαρμογές πραγματικού κόσμου. -
Υπεύθυνη ανοιχτή επιστήμη
: Η κυκλοφορία του μοντέλου με άδεια Creative Commons NonCommercial υπογραμμίζει τη δέσμευση της Meta για ανοιχτή επιστήμη και συνεργασία. Μοιράζοντας το μοντέλο με την ερευνητική κοινότητα, η Meta στοχεύει να προωθήσει την καινοτομία και να επιταχύνει την πρόοδο στην έρευνα τεχνητής νοημοσύνης, ωφελώντας τελικά την κοινωνία στο σύνολό της.
Ουσιαστικά, το μοντέλο V-JEPA της Meta έχει σημασία για την προώθηση της κατανόησης της τεχνητής νοημοσύνης, προσφέροντας ένα πιο αποτελεσματικό παράδειγμα μάθησης, διευκολύνοντας τη γενίκευση μεταξύ των εργασιών και συμβάλλοντας στις αρχές της ανοιχτής επιστήμης. Αυτές οι ιδιότητες συμβάλλουν στη σημασία της στο ευρύτερο τοπίο της έρευνας της τεχνητής νοημοσύνης και στον πιθανό αντίκτυπό της σε διάφορους τομείς.
VIA:
DataConomy.com
