Μετά την κυκλοφορία του Chat with RTX της NVIDIA, η AMD προσφέρει τώρα στους χρήστες το δικό τους τοπικό και βασισμένο σε GPT, το οποίο υποστηρίζεται από LLM, το οποίο μπορεί να λειτουργεί σε επεξεργαστές Ryzen AI και GPU Radeon 7000.
Το NVIDIA Chat με το RTX έχει ανταγωνιστή καθώς η AMD αποκαλύπτει το δικό της τοπικό Chatbot που υποστηρίζεται από LLM που μπορεί να τρέξει σε επεξεργαστές Ryzen AI και GPU Radeon 7000
Τον περασμένο μήνα, η NVIDIA κυκλοφόρησε το “Chat with RTX” AI Chatbot, το οποίο είναι διαθέσιμο σε όλες τις GPU RTX 40 & RTX 30 και επιταχύνεται με το σύνολο δυνατοτήτων TensorRT-LLM που προσφέρει ταχύτερα αποτελέσματα GenAI με βάση τα δεδομένα που της διαθέτετε από το Η/Υ ή με άλλους όρους, ένα τοπικό σύνολο δεδομένων. Τώρα η AMD προσφέρει το δικό της chatbot GPT που βασίζεται σε LLM, το οποίο μπορεί να τρέξει σε μια μεγάλη γκάμα υλικού, όπως οι υπολογιστές Ryzen AI, που περιλαμβάνουν Ryzen 7000 & Ryzen 8000 APU που διαθέτουν τις NPU XDNA μαζί με τις πιο πρόσφατες GPU Radeon 7000 που διαθέτουν επιταχυντές AI .
όπου παρέχει έναν οδηγό εγκατάστασης για το πώς να χρησιμοποιήσετε το υλικό του για να εκτελέσετε το δικό σας τοπικό chatbot που υποστηρίζεται από LLM που βασίζονται σε GPT (Μοντέλα Μεγάλων Γλωσσών). Για επεξεργαστές AMD Ryzen AI, μπορείτε να αποκτήσετε το
τυπικό αντίγραφο LM Studio για Windows
3. Στην καρτέλα αναζήτησης αντιγράψτε και επικολλήστε τον ακόλουθο όρο αναζήτησης ανάλογα με το τι θέλετε να εκτελέσετε:
ένα. Εάν θέλετε να εκτελέσετε το Mistral 7b, αναζητήστε:
TheBloke/OpenHermes-2.5-Mistral-7B-GGUF
” και επιλέξτε το από τα αποτελέσματα στα αριστερά. Συνήθως θα είναι το πρώτο αποτέλεσμα. Θα πάμε με το Mistral σε αυτό το παράδειγμα.
σι. Εάν θέλετε να εκτελέσετε το LLAMA v2 7b, αναζητήστε:
TheBloke/Llama-2-7B-Chat-GGUF
” και επιλέξτε το από τα αποτελέσματα στα αριστερά. Συνήθως θα είναι το πρώτο αποτέλεσμα.
ντο. Μπορείτε επίσης να πειραματιστείτε με άλλα μοντέλα εδώ.
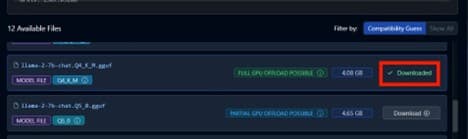
4. Στο δεξιό πλαίσιο, κάντε κύλιση προς τα κάτω μέχρι να δείτε το
Q4 χλμ
αρχείο μοντέλου. Κάντε κλικ στη λήψη.
ένα. Συνιστούμε
Q4 χλμ
για τα περισσότερα μοντέλα σε Ryzen AI. Περιμένετε να ολοκληρωθεί η λήψη.
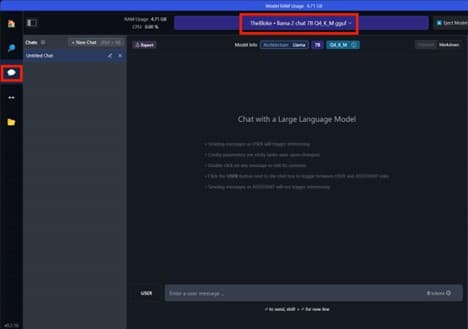
5. Μεταβείτε στην καρτέλα συνομιλίας. Επιλέξτε το μοντέλο από το κεντρικό, αναπτυσσόμενο μενού στο επάνω κέντρο και περιμένετε να ολοκληρωθεί η φόρτωσή του.
6. Εάν έχετε ένα
AMD
Ryzen AI PC
μπορείτε να αρχίσετε να συνομιλείτε!
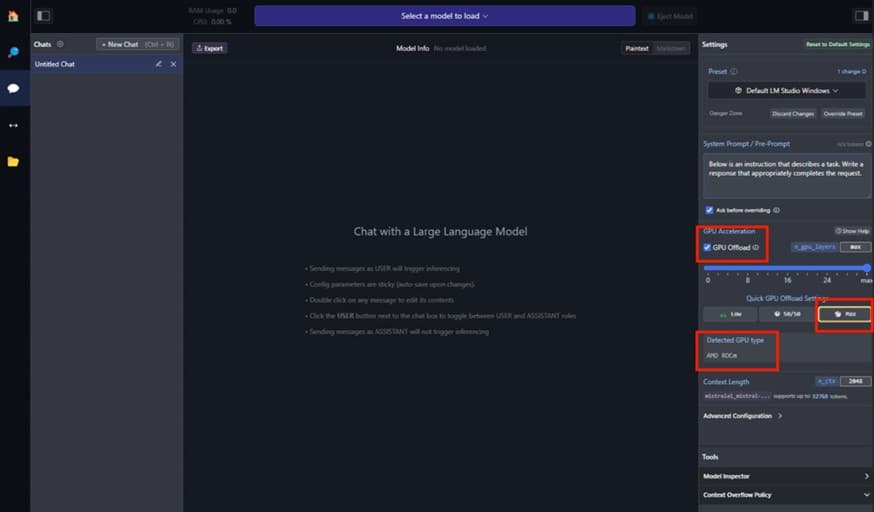
ένα. Εάν έχετε ένα
AMD
Κάρτα γραφικών Radeon
σας παρακαλούμε:
Εγώ. Επιλέξτε “Αποφόρτωση GPU” στο δεξιό πλαίσιο.
ii. Μετακινήστε το ρυθμιστικό μέχρι το «Max».
iii. Βεβαιωθείτε ότι το AMD ROCm εμφανίζεται ως ο εντοπισμένος τύπος GPU.
iv. Ξεκινήστε να συζητάτε!
Η ύπαρξη ενός τοπικού chatbot που τροφοδοτείται από AI μπορεί να κάνει τη ζωή και την εργασία σχετικά πιο εύκολη εάν ρυθμιστεί σωστά. Μπορείτε να είστε αποτελεσματικοί στην εκτέλεση της δουλειάς σας και να έχετε σωστά αποτελέσματα με βάση τα ερωτήματά σας και τη διαδρομή δεδομένων στην οποία στοχεύει το LLM. Η NVIDIA και η AMD επιταχύνουν τον ρυθμό των χαρακτηριστικών που τροφοδοτούνται με τεχνητή νοημοσύνη για υλικό καταναλωτικής βαθμίδας και αυτή είναι μόνο η αρχή, αναμένετε περισσότερες καινοτομίες στο δρόμο καθώς το τμήμα υπολογιστών τεχνητής νοημοσύνης φτάνει σε νέα ύψη.
Αφοσιωμένος λάτρης κινητών Samsung, ο Δημήτρης έχει εξελίξει μια ιδιαίτερη σχέση με τα προϊόντα της εταιρίας, εκτιμώντας τον σχεδιασμό, την απόδοση και την καινοτομία που προσφέρουν.
Γράφοντας και διαβάζοντας τεχνολογικά νέα από όλο τον κόσμο.